
Перевод статьи “How to Match Parentheses in JavaScript without Using Regex”.
При написании интерпретатора Lisp (точнее, его диалекта — Scheme) я решил включить поддержку квадратных скобок. Дело в том, что в некоторых книгах по Scheme они используются наравне с круглыми. Но я не хотел слишком усложнять парсер, поэтому не стал проверять, совпадают ли скобки в парах.
В моем интерпретаторе Lisp скобки можно было бы смешать следующим образом:
(let [(x 10]) [+ x x)]
Приведенный выше код — это пример S-выражения, в котором есть токены — последовательности символов со значением (например, let или число 10) — и круглые и квадратные скобки. Но этот код невалиден из-за того, что пары круглых и квадратных скобок не совпадают.
(let [(x 10)] [+ x x])
А вот это — правильный синтаксис Lisp (если скобки поддерживаются). Открывающие круглые скобки всегда совпадают с закрывающими круглыми скобками, а открывающие квадратные скобки всегда совпадают с закрывающими квадратными.
В этой статье я покажу, как можно определить, является ли входное сообщение валидным S-выражением, т.е. таким, как во втором примере, а не в первом.
Мы также разберемся с такими случаями, как этот:
(define foo 10))))
Здесь вы видите недопустимый синтаксис, в котором закрывающих скобок больше, чем открывающих.
Проще говоря, мы будем определять, совпадают ли пары открывающих и закрывающих символов (), [] и {} внутри строки типа «[foo () {bar}]».
Решение этой задачи может пригодиться при реализации синтаксического анализатора Lisp, но вы можете использовать его и для других целей (например, для валидации или для вычисления математических выражений). Это также хорошее упражнение.
Примечание. Для понимания этой статьи и кода в примерах вам не нужно ничего знать о Lisp.
Использование стека
Вы можете подумать, что самый простой способ решить эту задачу — использовать регулярные выражения (RegExp). Возможно, для простых случаев это подойдет, но вскоре выражение станет слишком сложным и будет скорее создавать проблемы, чем решать их.
На самом деле, самый простой способ сопоставления открывающих и закрывающих символов — это использование стека. Стек — это простейшая структура данных. У нас есть две основные операции: push — для добавления элемента в стек и pop — для удаления элемента.
Это похоже на стопку книг. Последняя книга, которую вы положили в стопку, будет первой, которую вы уберете.
С помощью стека легче обрабатывать (парсить) символы, которые имеют начало и конец, например XML-теги или простые круглые скобки.
Например, у нас есть такой XML-код:
<element><item><sub-item>text</sub-item></item></element>
Когда мы используем стек, последний тег, который мы открываем (например, внутренний <sub-item>), всегда будет первым, который нам нужно закрыть (если XML валиден).
То есть мы можем добавлять в стек (push) элемент <sub-item>, когда открываем его, и изымать из стека (pop), когда необходимо этот элемент закрыть. Все, что нам нужно, — следить за тем, чтобы последний элемент в стеке, который всегда является открывающим тегом, совпадал с закрывающим.
Та же логика работает и со скобками.
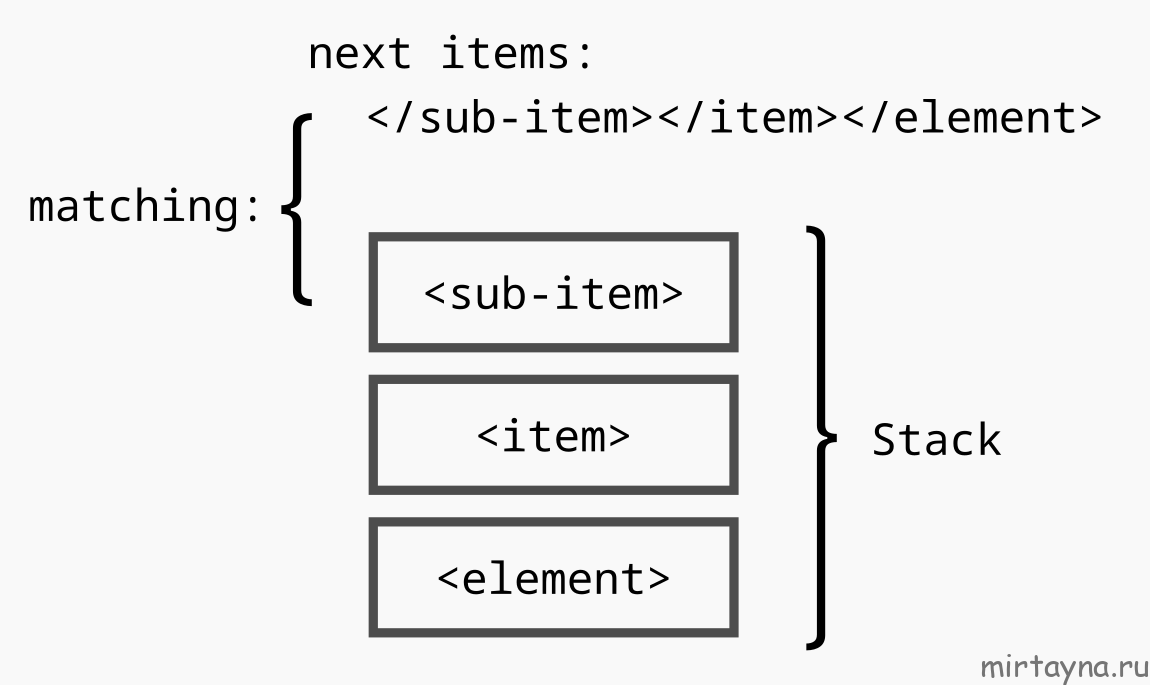
Обратите внимание, что самозакрывающиеся теги XML можно пропускать, так как они открываются и автоматически закрываются.
Массивы в JavaScript имеют методы push и pop, поэтому их можно использовать как стек. Но удобнее создать абстракцию в виде класса, чтобы добавить дополнительные методы, такие как top() и is_empty(), которые легче читать. Впрочем, даже если бы мы не добавляли новые методы, всегда лучше создавать подобные абстракции, потому что это делает код проще и легче для чтения.
class Stack {
#data;
constructor() {
// creating new empty array as hidden property
this.#data = [];
}
push(item) {
// push method just use native Array::push()
// and add the item at the end of the array
this.#data.push(item);
}
len() {
// size of the Stack
return this.#data.length;
}
top() {
// sice the items are added at the end
// the top of the stack is the last item
return this.#data[this.len() - 1];
}
pop() {
// pop is similar to push and use native Array::pop()
// it removes and returns the last item in array
return this.#data.pop();
}
is_empty() {
// this comment shortcut !0 is true
// since 0 can is coerced to false
return !this.len();
}
}В приведенном выше коде используется класс ES6 (ES2015) и приватные свойства ES2022.
Алгоритм сопоставления скобок
Теперь я опишу шаги, необходимые для парсинга круглых скобок.
Нам нужен цикл, который будет проходить через каждый токен — и лучше всего, если все остальные токены будут удалены перед обработкой.
Когда у нас есть открывающая скобка, мы должны поместить этот элемент в стек. Когда у нас есть закрывающая скобка, нам нужно проверить, совпадает ли последний элемент в стеке с тем, который мы обрабатываем.
Если элемент совпадает, мы удаляем его из стека. В противном случае мы перепутали скобки и должны выбросить исключение.
Если у нас есть закрывающая скобка, но в стеке ничего нет, нам также нужно выбросить исключение, потому что нет открывающей скобки, которая бы совпадала с закрывающей.
После проверки всех символов (токенов), если в стеке что-то осталось, это означает, что мы не закрыли все скобки. Но это не страшно, ведь пользователь может находиться в процессе написания. Поэтому в этом случае мы возвращаем false, а не исключение.
Если стек пуст, мы возвращаем true. Это означает, что у нас есть полное выражение. Если бы это было S-выражение, мы могли бы использовать парсер для его обработки, и нам не пришлось бы беспокоиться о невалидных результатах.
Исходный код
function balanced(str) {
// pairs of matching characters
const maching_pairs = {
'[': ']',
'(': ')',
'{': '}'
};
const open_tokens = Object.keys(maching_pairs);
const brackets = Object.values(maching_pairs).concat(open_tokens);
// we filter out what is not our matching characters
const tokens = tokenize(str).filter(token => {
return brackets.includes(token);
});
const stack = new Stack();
for (const token of tokens) {
if (open_tokens.includes(token)) {
stack.push(token);
} else if (!stack.is_empty()) {
// there are matching characters on the stack
const last = stack.top();
// the last opening character needs to match
// the closing bracket we have
const closing_token = maching_pairs[last];
if (token === closing_token) {
stack.pop();
} else {
// the character don't match
throw new Error(`Syntax error: missing closing ${closing_token}`);
}
} else {
// this case when we have closing token but no opening one,
// becauase the stack is empty
throw new Error(`Syntax error: not matched closing ${token}`);
}
}
return stack.is_empty();
}Приведенный выше код был реализован как часть моего парсера S-выражений, но единственное, что я использовал из той статьи, — это функция tokenize(), которая разбивает строку на токены (где токен — это один объект, например число 123 или строка «hello»). Если вы хотите обрабатывать только символы, вы можете использовать str.split(''), тогда токены будут представлять собой массив символов.
Этот код намного проще, чем парсер S-выражений, потому что нам не нужно обрабатывать все токены. Но, используя функцию tokenize() из упомянутой выше статьи, мы сможем проверять вводимые данные:
(this "))))")
Полный исходный код (включая функцию tokenize()) можно найти на GitHub.
Резюме
Не стоит даже начинать обрабатывать выражения, содержащие открывающие и закрывающие символы, с помощью регулярных выражений. На StackOverflow есть обсуждение этой темы: RegEx match open tags except XHTML self-contained tags.
Сопоставление скобок представляет собой точно такую же проблему, как и парсинг HTML. Как видно из приведенного выше кода, проблема решается проще, если мы используем стек.
Возможно, мы могли бы написать регулярное выражение, которое проверяло бы, есть ли в последовательности символов совпадающие круглые скобки. Но это быстро усложнится, если в качестве токенов (последовательностей символов) будут выступать строки, как в S-выражениях, а круглые скобки внутри этих строк будут игнорироваться. А ведь подобную задачу можно решить довольно просто, если применить более подходящие инструменты.
Лично я люблю регулярные выражения, но, если вы намерены их применить, всегда стоит задуматься, будет ли это наилучшим решением.
Запись Как сопоставлять скобки с помощью JavaScript и без использования Regex впервые появилась techrocks.ru.


